当ページでは、CSA Data Uploaderで利用可能な変換・加工処理の一覧を紹介します。
変換・加工処理一覧¶
列操作¶
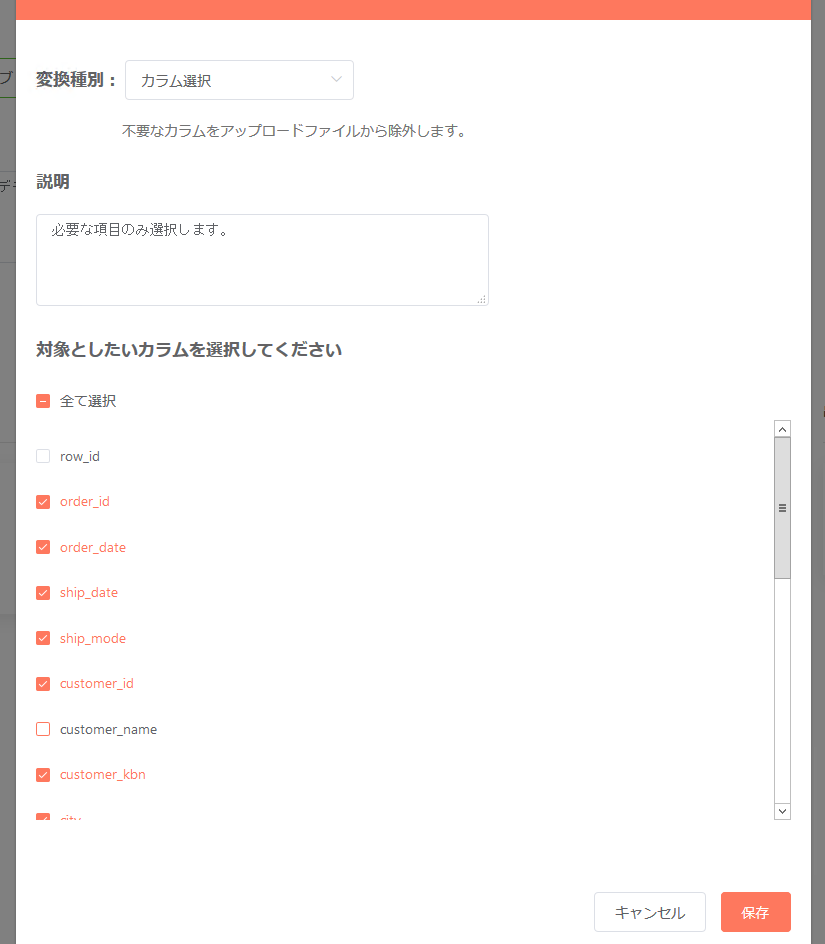
カラム選択¶
分析環境にアップロードする際に不要なカラムを(ファイル時点で)除去しておきたい場合、「カラム選択」を使う事でカラム毎の選択・除去が行えます。
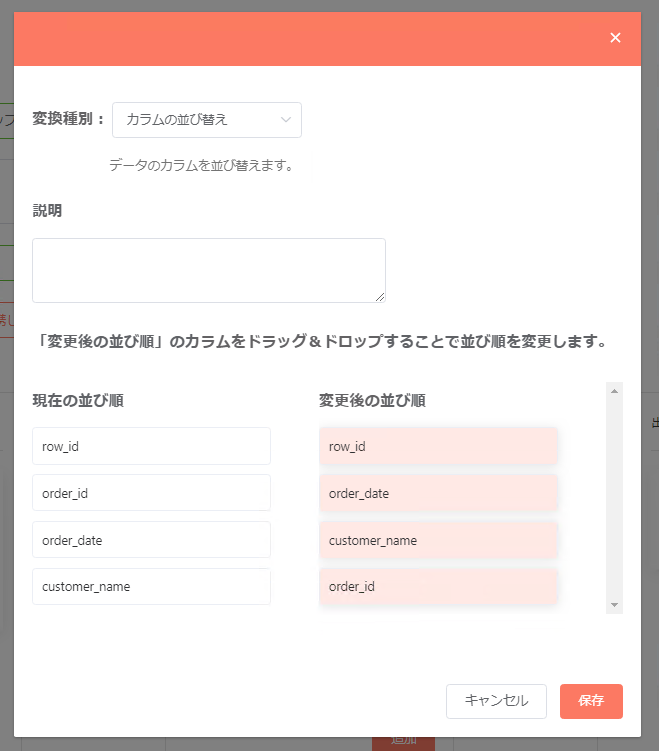
カラムの並び替え¶
対象となるカラムの順番を変更したい場合、「カラムの並び替え」を使うことで任意の順番での入力ファイルのカラム表示位置の変更が行えます。
カラムの追加¶
データに基づいたカラムを別途用意したい場合、「カラムの追加」を使うことで任意の値を持ったカラムを追加することが出来ます。
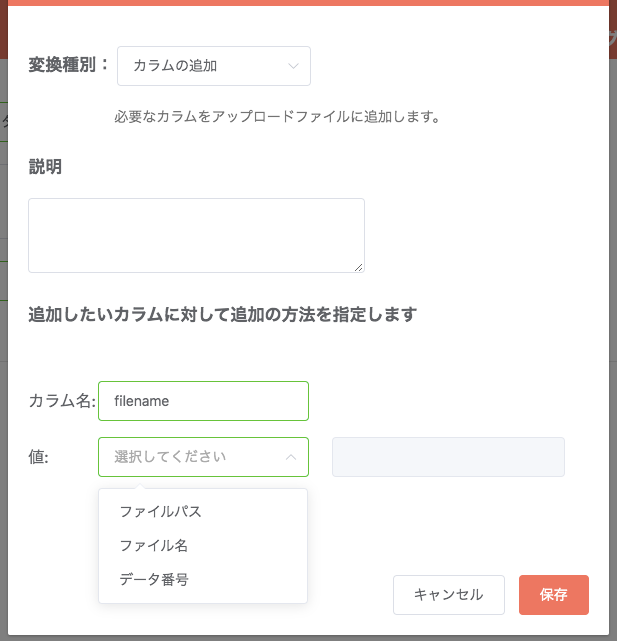
利用可能な選択肢は以下の通り。
- ファイルパス(=バケット配下のフォルダ及びファイル名)
- ファイル名(ファイルパスからフォルダ部分を除いたもの)
- データ番号(1始まりで1ずつ増分)
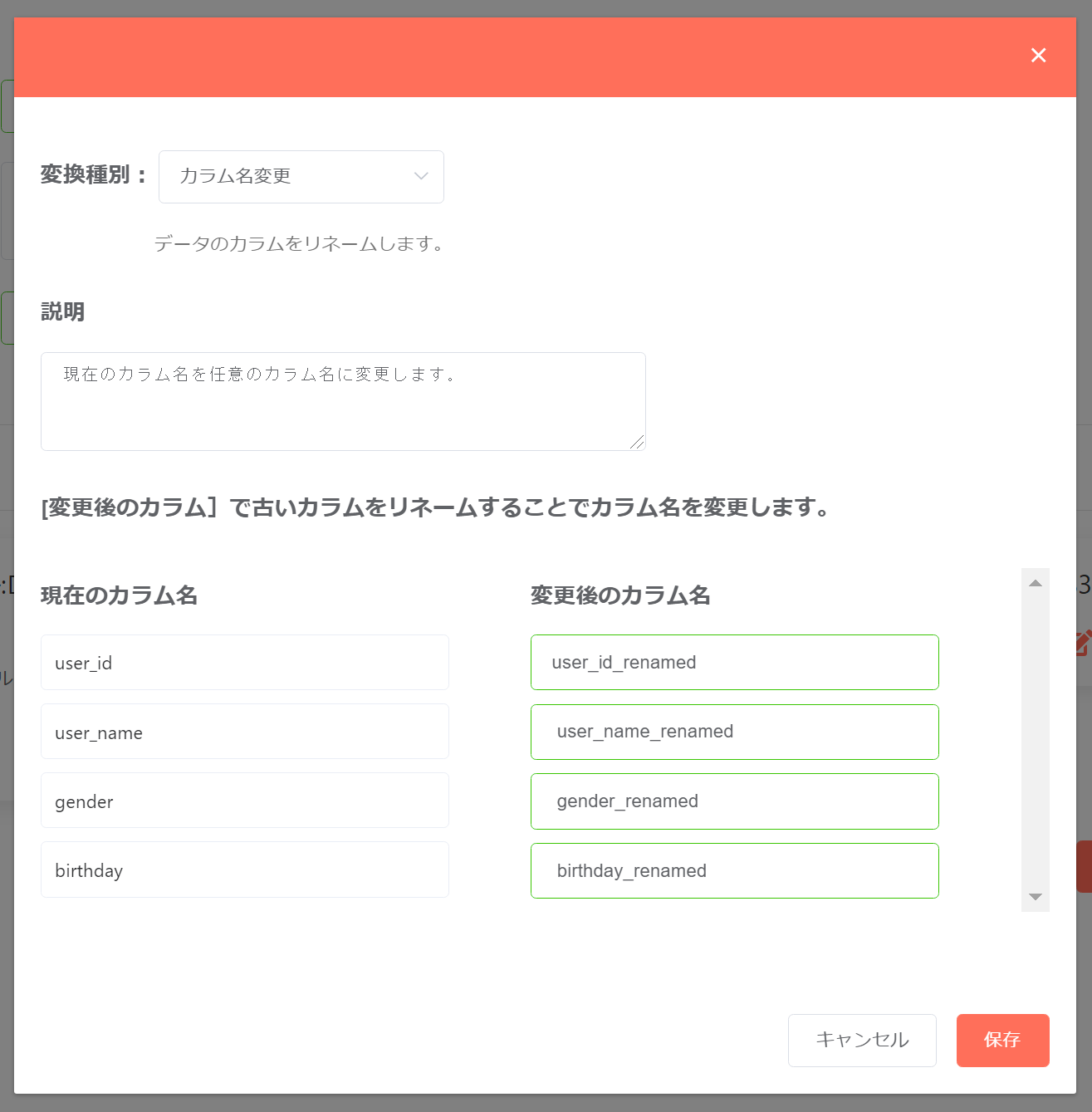
カラム名変更¶
対象となるカラムの名称を変更したい場合、「カラム名変更」を使うことで任意の名称変更を行うことが出来ます。
行列変換¶
入力データの行と列の内容を任意の形式で入れ替えた形としたい場合、「行列変換」を使うことで処理を実現出来ます。
任意の列構造を持つデータに対し、以下の指定を行うことで変換を行います。
- キーに対して行の情報を維持する列(カラム)
- 行列変換実施後にカテゴリ項目の列(カラム)名称
- 行列変換実施後に数値項目の列(カラム)名称
変換前のデータ例:
![]()
指定内容:
![]()
変換後のデータ例:
![]()
列分割¶
入力データの任意の列の内容をある条件で分割したい場合、「列分割」を使うことで処理を実現出来ます。
行データに対し、以下の指定を行うことで変換を行います。
- 分割対象となる列(カラム)
- 分割する数(2〜10を指定可能、指定数を超えて分割された情報は破棄されます)
- 分割の方法(任意の桁数、または任意の区切り文字)
変換例1).対象項目を2桁ずつ最大3つまで分割
![]()
変換例1).変換後の値
![]()
変換例2).対象項目を「-」毎に分割、最大3つまで
![]()
変換例2).変換後の値
![]()
既存列を結合(日付作成)¶
既存の列情報を結合する形で、新たに日付型の列を作成します。作成には「年」「月」「日」に相当する項目を必要としますが、固定値を設定する事も可能です。
変換前のデータ例:
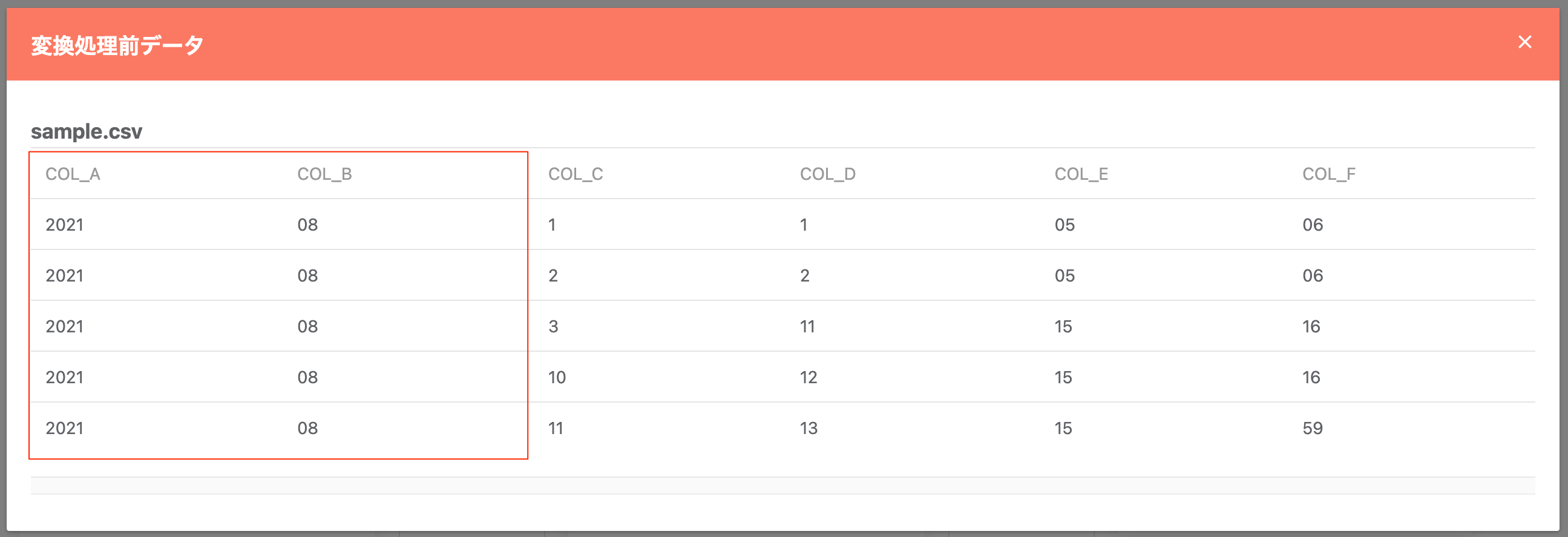
指定内容:
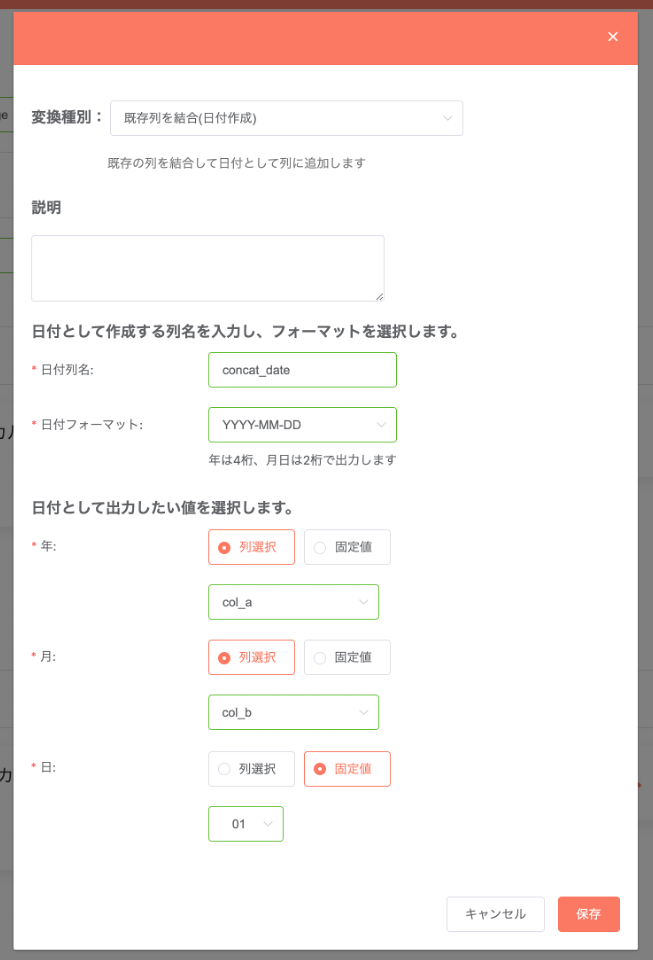
変換後のデータ例:
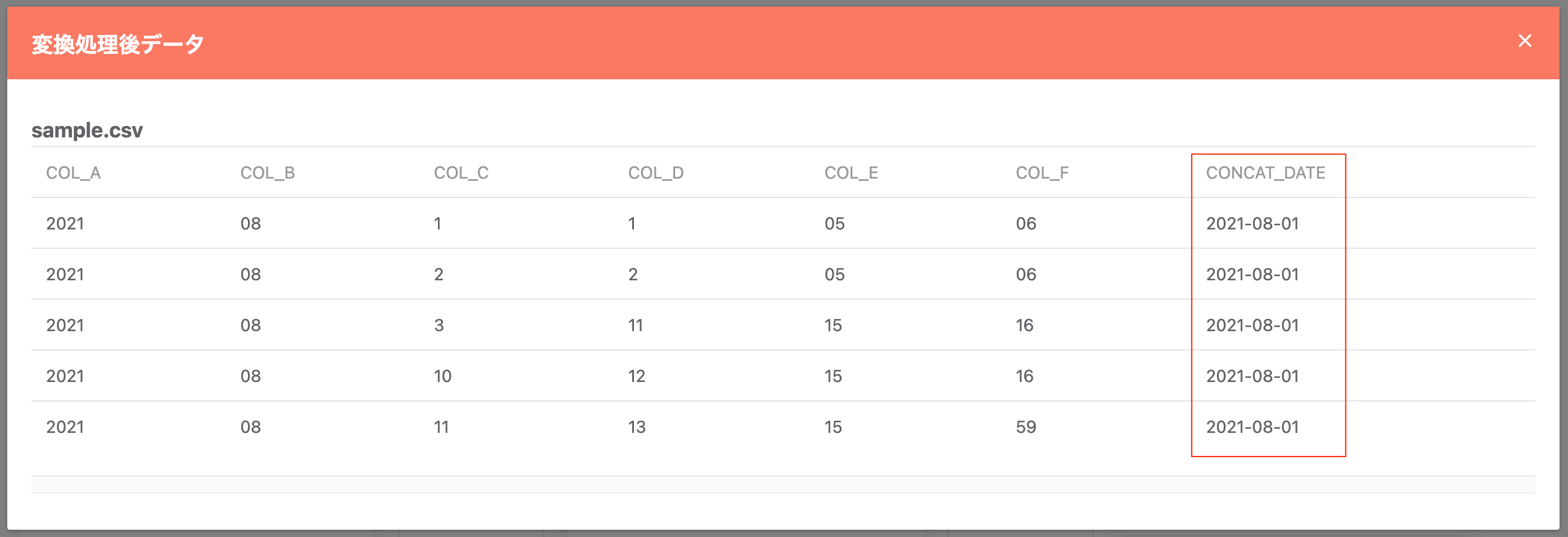
既存列を結合(タイムスタンプ作成)¶
既存の列情報を結合する形で、新たにタイムスタンプ型の列を作成します。作成には「年」「月」「日」及び「時」「分」「秒」に相当する項目を必要としますが、固定値を設定する事も可能です。
変換前のデータ例:
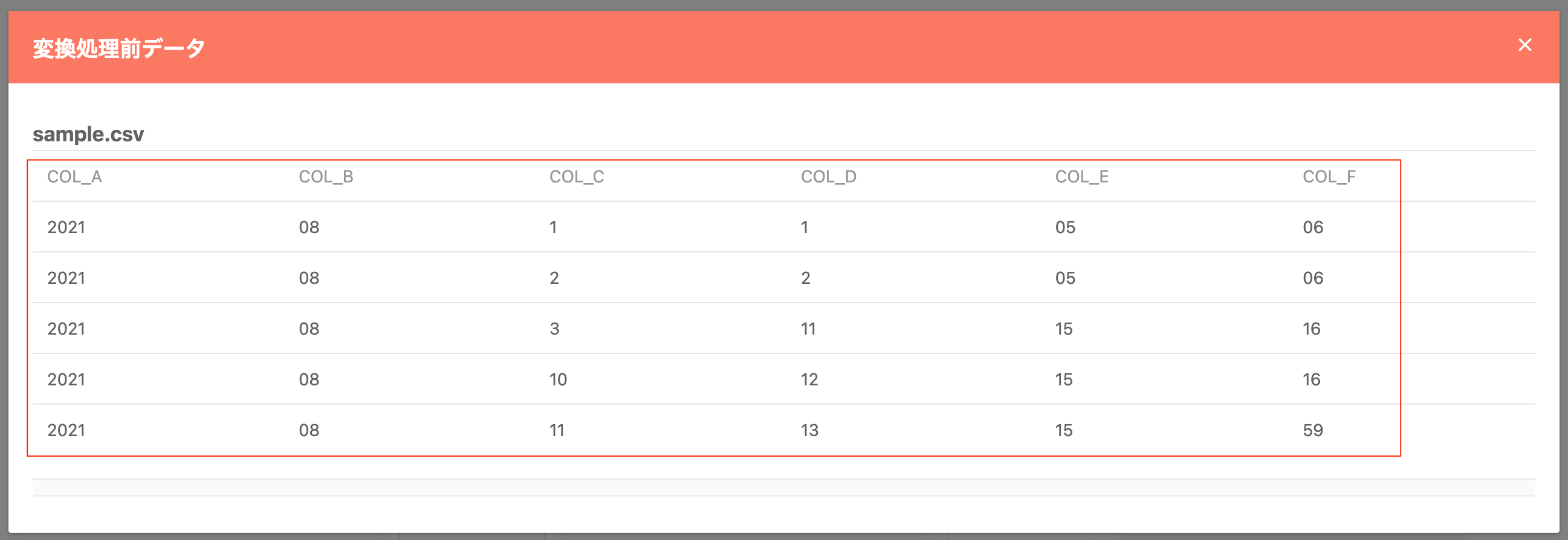
指定内容:
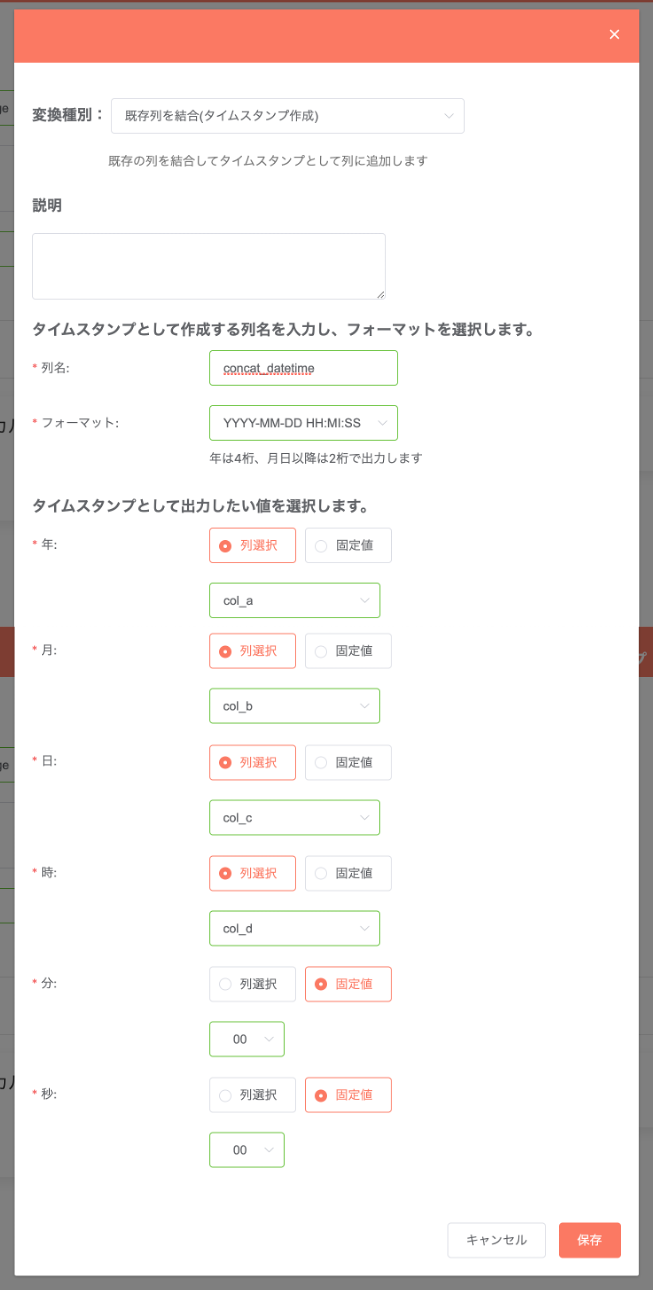
変換後のデータ例:
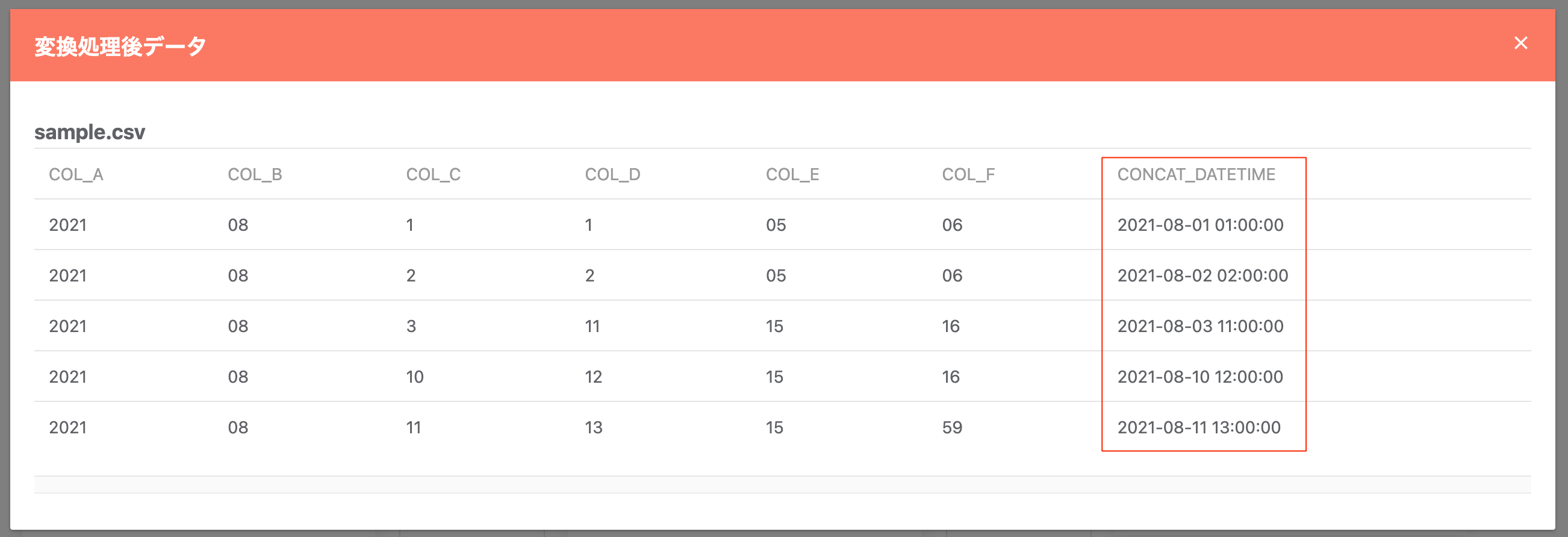
行操作¶
行分割¶
行の内容を指定の条件で分割したい場合、「行分割」を使うことで処理を実現出来ます。
行データに対し、以下の指定を行うことで変換を行います。
- 行の中で「分割」を行う対象列(カラム)
- 区切り文字
変換前のデータ:
![]()
指定内容:
![]()
変換後のデータ:
![]()
データ整形(列毎に整形)¶
マスキング¶
何らかの理由によりカラムの値を所定の文字で埋める等のマスク処理を行いたい場合、「マスキング」を使う事で指定したカラムに対して所定のマスク処理を施す事が出来ます。マスク処理の方法はカラム毎に個別指定が可能です。
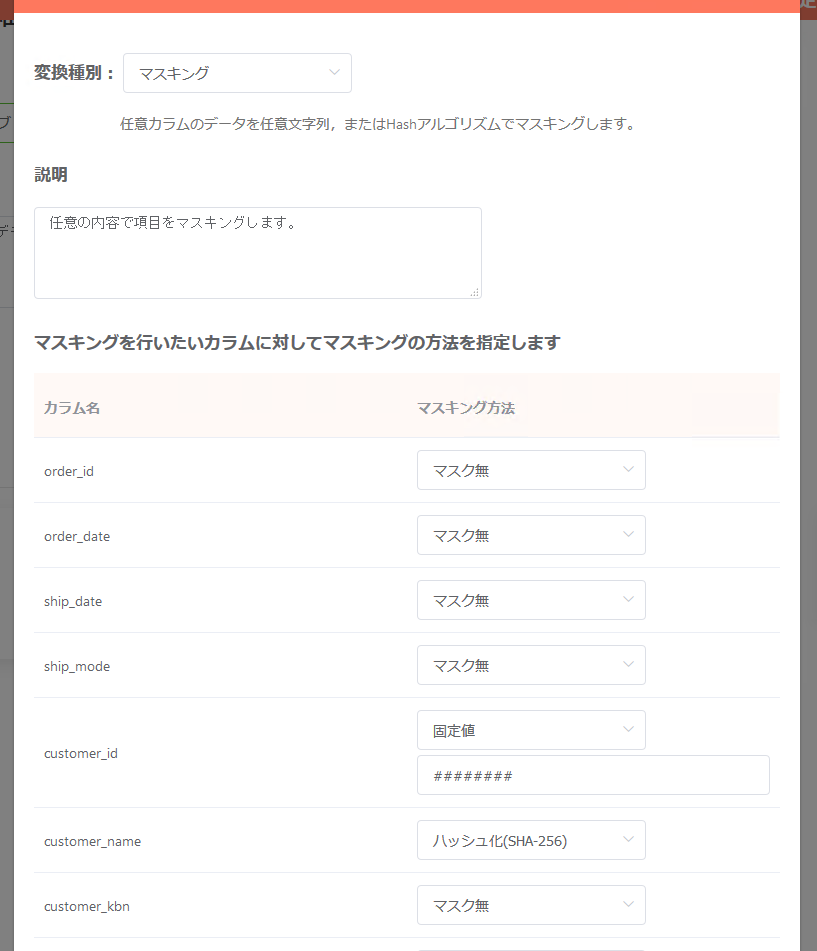
部分抽出¶
「指定された文字位置にある指定された文字数の文字を、文字列から抽出して返す」処理を行いたい場合、「部分抽出」を使う事で任意の文字列抽出を行えます。カラム毎の個別指定が可能となっています。
処理の挙動はAmazon Redshiftにおける「substring」関数と同様です。
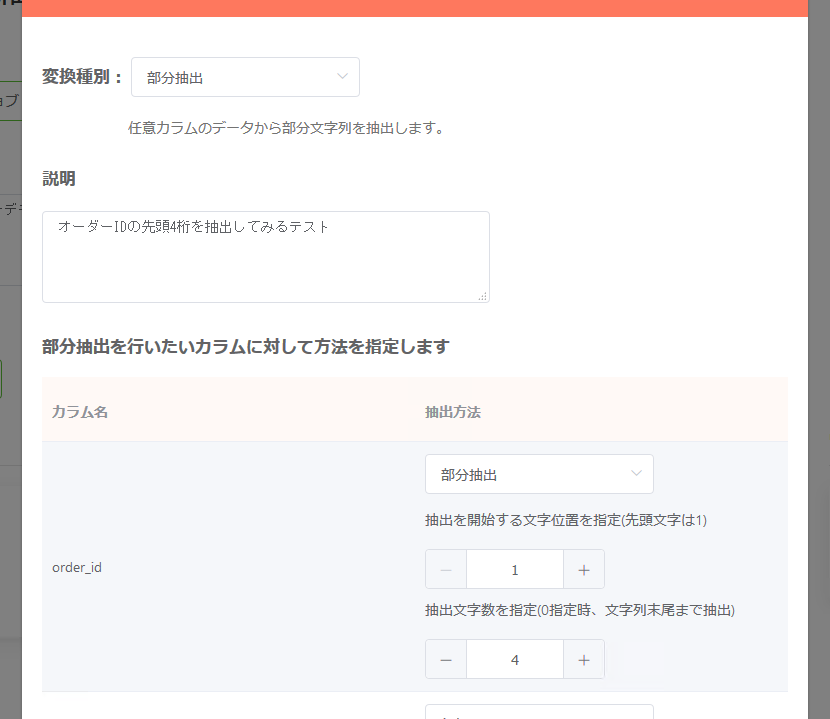
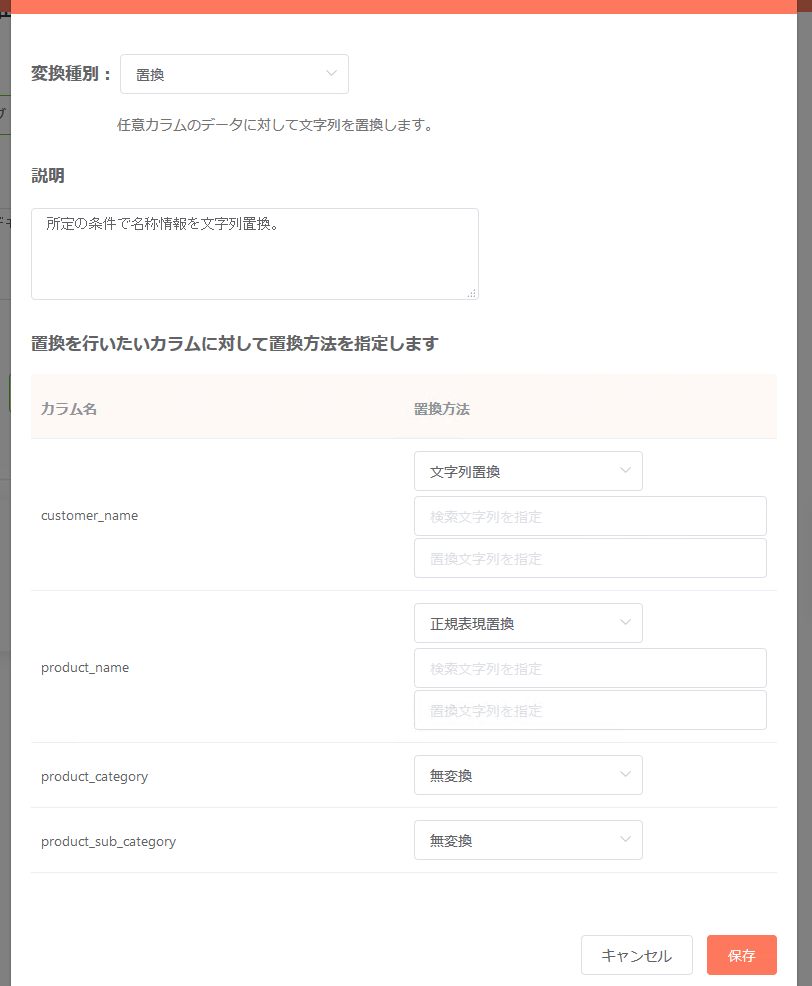
置換¶
「対象文字列内の条件に合致する要素を、指定した文字列に変換する」処理を行いたい場合、「置換」を使う事で実現が可能です。カラム毎の個別指定が可能となっています。
変換のタイプは下記2種類が選択可能です。
- 文字列置換:合致する条件の文字列(検索文字列)、条件に合致した文字列をどのような文字列に置き換えるか(置換文字列)を指定。
- 正規表現置換:正規表現を用いて検索を行いたい文字列(検索文字列)、条件に合致した文字列をどのような文字列に置き換えるか(置換文字列)を指定
- 正規表現のシンタックスについては、Googleがライブラリとして提供している『RE2』に準拠しています。
制御文字の削除¶
ヌル文字やバックスペースに代表される「制御文字」を所定のカラムから除去したい場合、「制御文字の削除」を使う事で実現が可能です。カラム毎の個別指定が可能となっています。
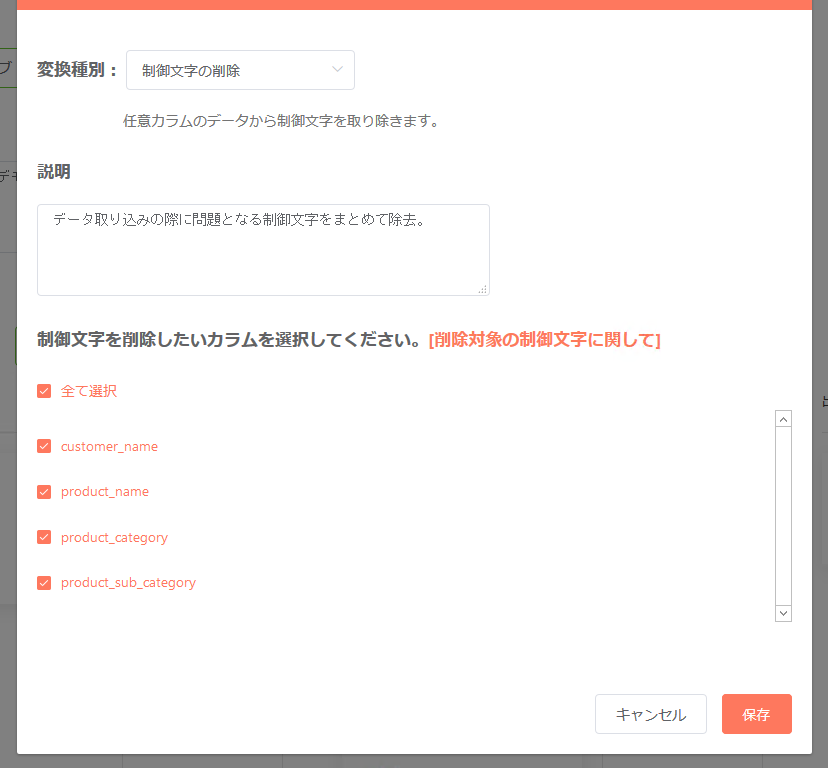
- タブ文字・改行文字は当処理では対象外となっています。
- 対象となる制御文字の一覧は以下の通りです。
| 略語 | 値(16進数) | 名前/意味 |
|---|---|---|
| NUL | 0x00 | ヌル文字 |
| SOH | 0x01 | ヘディング開始 |
| STX | 0x02 | テキスト開始 |
| ETX | 0x03 | テキスト終了 |
| EOT | 0x04 | 伝送終了 |
| ENQ | 0x05 | 問い合わせ |
| ACK | 0x06 | 肯定応答 |
| BEL | 0x07 | ベル |
| BS | 0x08 | バックスペース |
| VT | 0x0B | 垂直タブ |
| FF | 0x0C | 書式送り |
| SO | 0x0E | シフトアウト |
| SI | 0x0F | シフトイン |
| DLE | 0x10 | 伝送制御拡張 |
| DC1 | 0x11 | 装置制御1 |
| DC2 | 0x12 | 装置制御2 |
| DC3 | 0x13 | 装置制御3 |
| DC4 | 0x14 | 装置制御4 |
| NAK | 0x15 | 否定応答 |
| SYN | 0x16 | 同期信号 |
| ETB | 0x17 | 伝送ブロック終結 |
| CAN | 0x18 | 取消 |
| EM | 0x19 | 媒体終端 |
| SUB | 0x1A | 置換 |
| ESC | 0x1B | エスケープ |
| FS | 0x1C | ファイル分離 |
| GS | 0x1D | グループ分離 |
| RS | 0x1E | レコード分離 |
| US | 0x1F | ユニット分離 |
| DEL | 0x7F | 削除 |
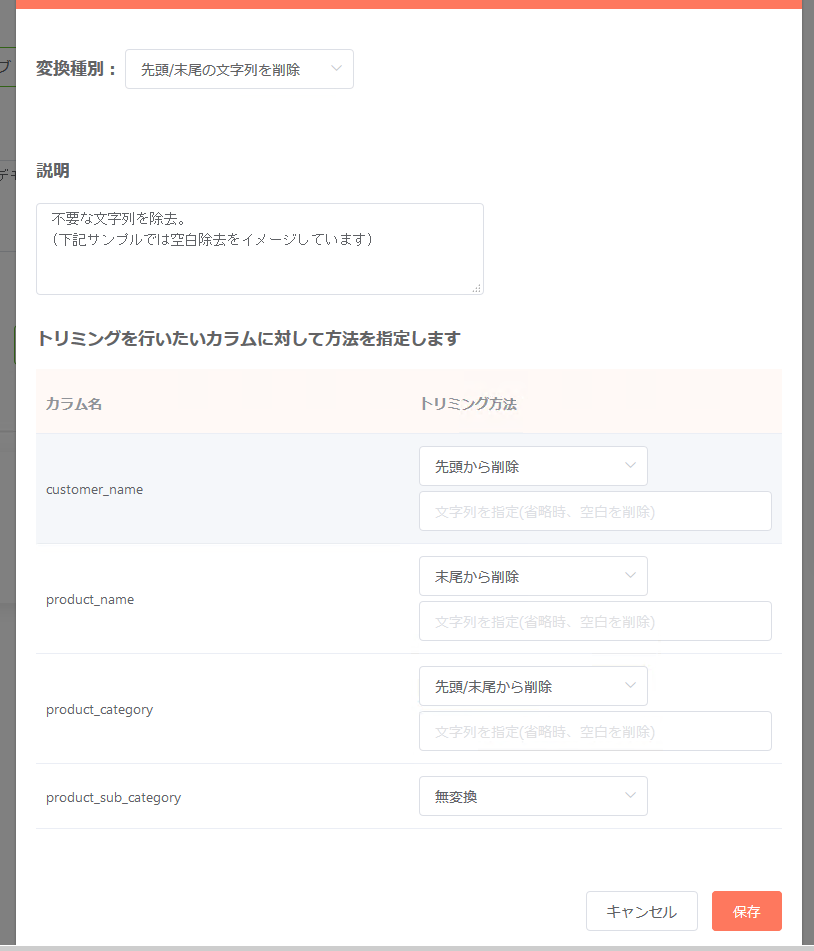
先頭/末尾の文字列を削除¶
任意の文字列を対象カラムから除去したい場合、「先頭/末尾の文字列を削除」を使うことで実現が可能です。カラム毎の個別指定が可能となっています。
- 除去する文字列が未入力の場合、所定の条件で「空白を除去」する挙動となります。
- ここでの「空白」の定義は以下のものが該当します。
- 半角空白
- 全角空白を削除対象としたい場合は任意の文字列として全角空白を入力してください。
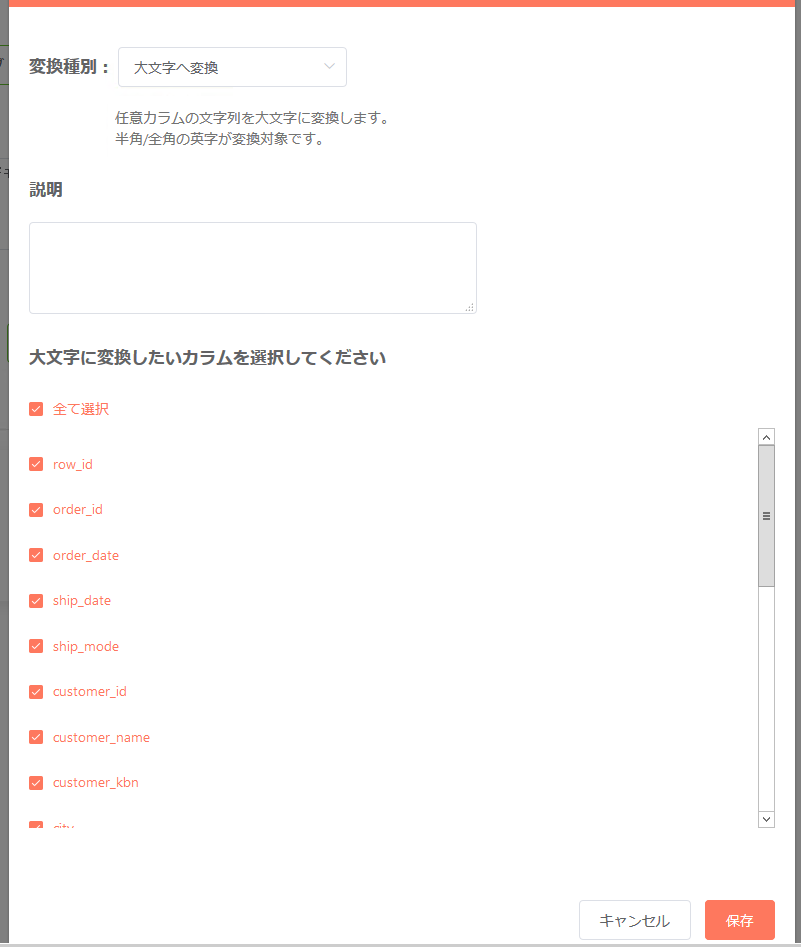
大文字へ変換¶
対象カラムの英字文字列を全て大文字に変換したい場合、「大文字へ変換」を使う事で実現が可能です。
- 対象となる英字文字列は半角及び全角のものが対象となります。
- 上記以外の文字列は変換対象には含まれません。
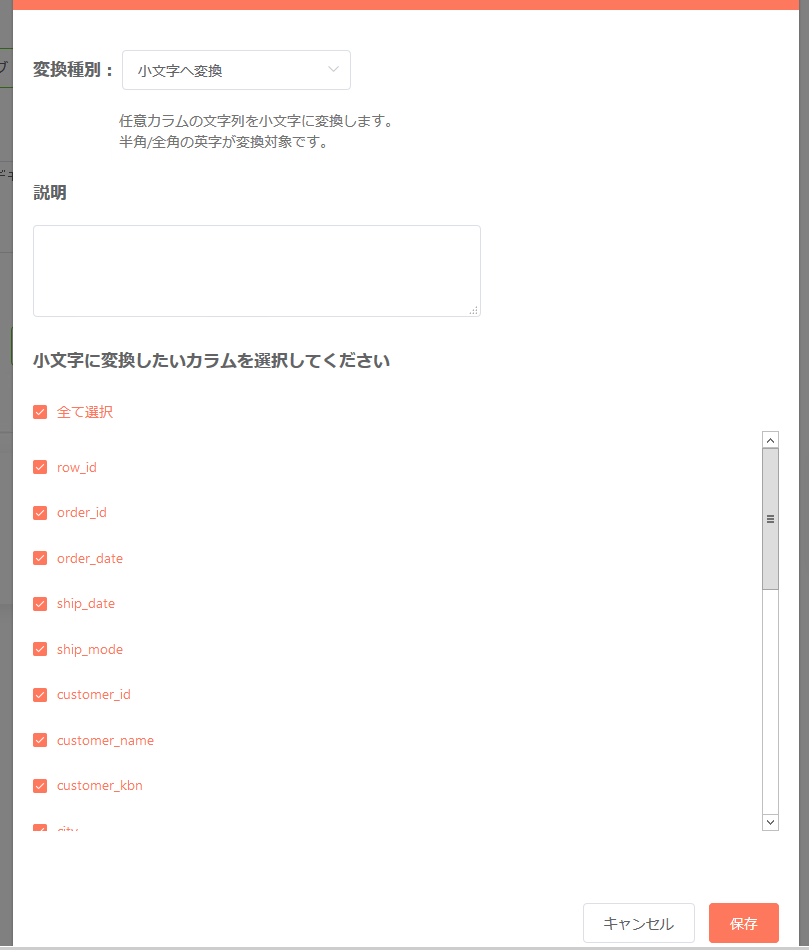
小文字へ変換¶
対象カラムの英字文字列を全て小文字に変換したい場合、「小文字へ変換」を使う事で実現が可能です。
- 対象となる英字文字列は半角及び全角のものが対象となります。
- 上記以外の文字列は変換対象には含まれません。
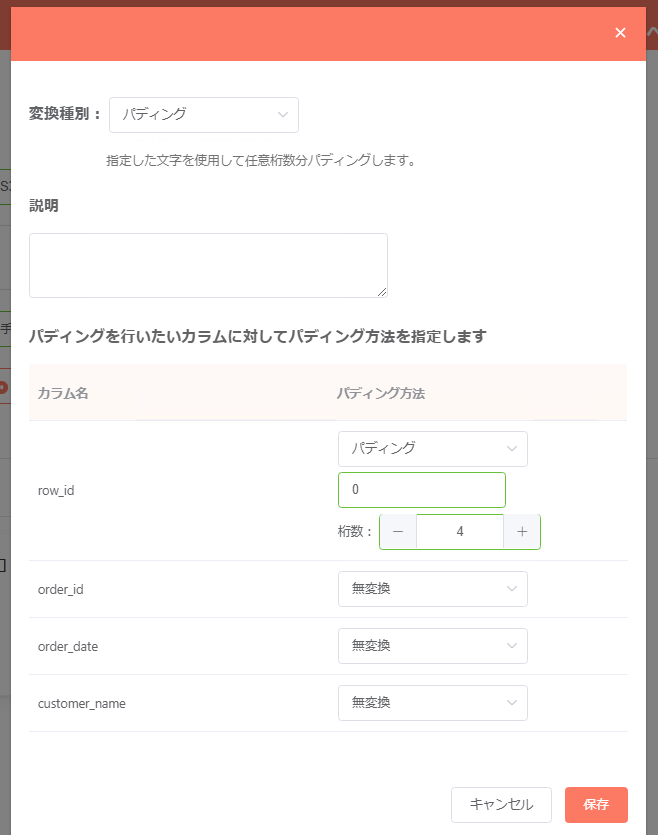
パディング¶
対象カラムの空白文字・余白部分を任意の文字で任意の桁数分埋めたい(パディング)処理を行いたい場合、「パディング」を使うことで文字列加工を行えます。
処理の挙動はAmazon Redshiftにおける「LPAD/RPAD」関数と同様です。
データ整形(形式を統一)¶
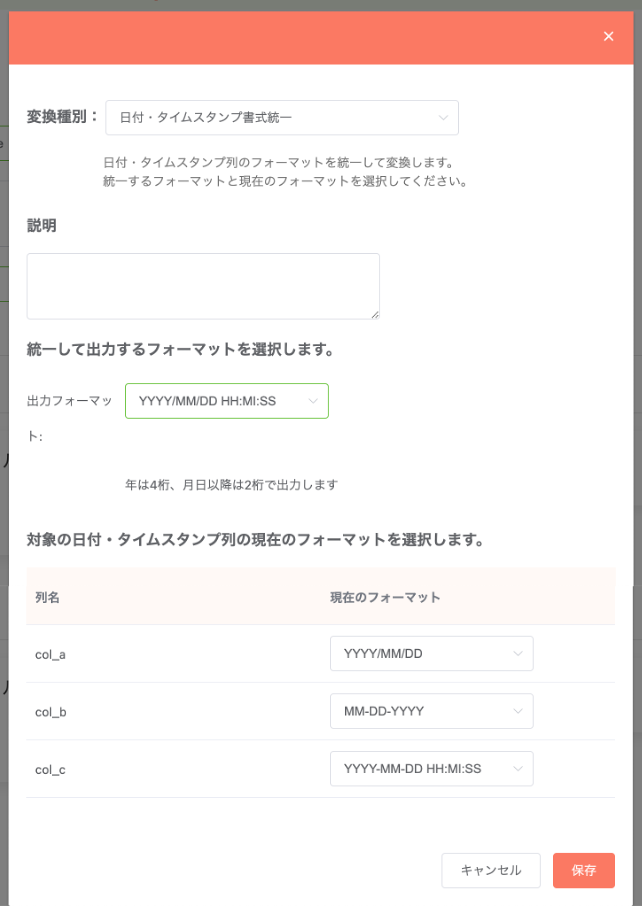
日付・タイムスタンプ 書式統一¶
入力データソースで指定した項目の日付・タイムスタンプ列の書式を、指定した書式に統一します。
Note
同一データソース内で異なる書式の列が混在していた場合に便利です。
変換前のデータ例:
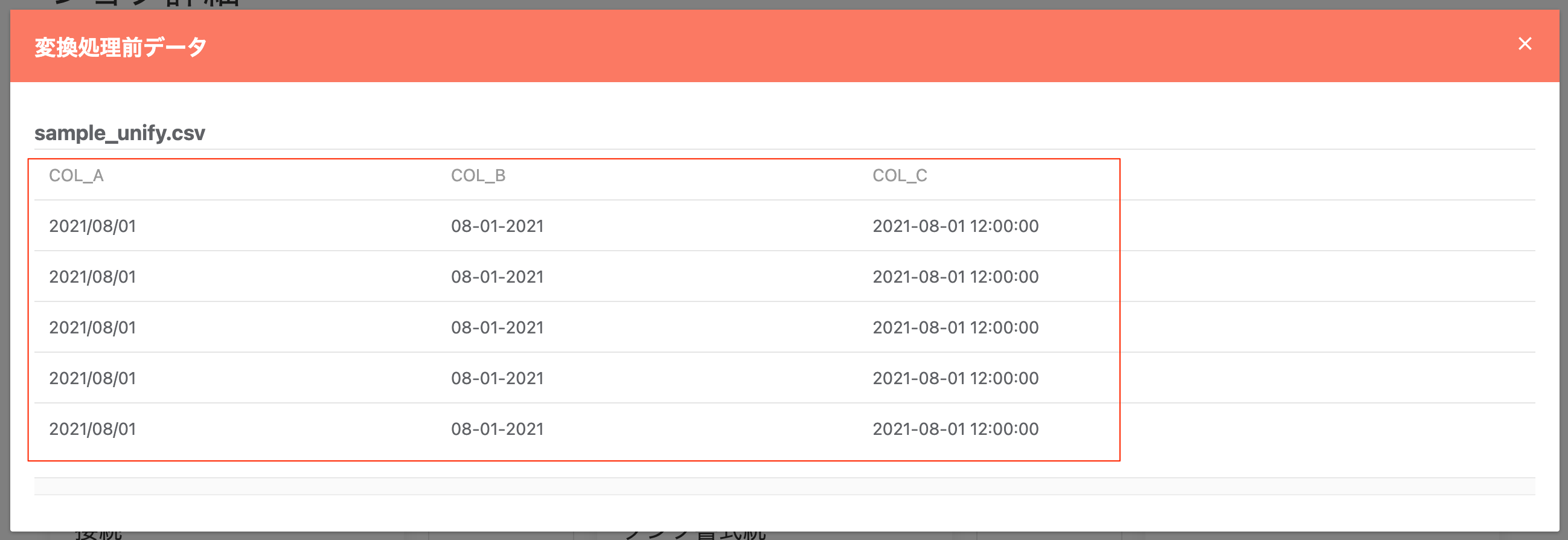
指定内容:
変換後のデータ例:
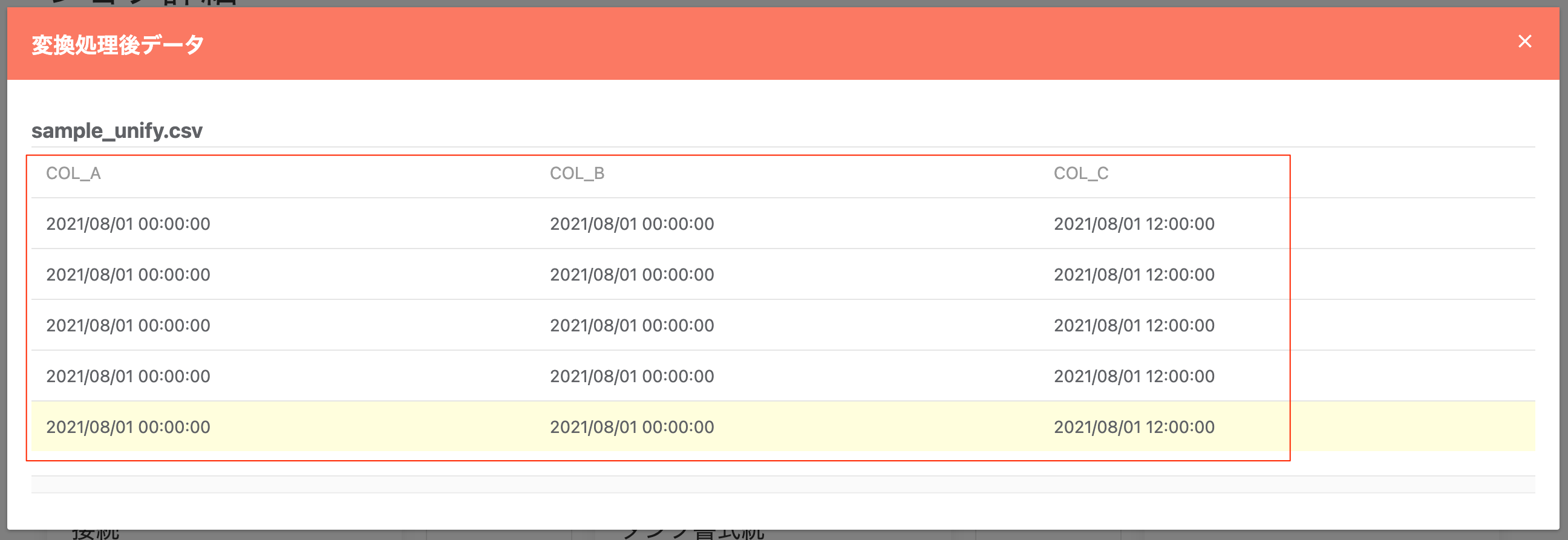
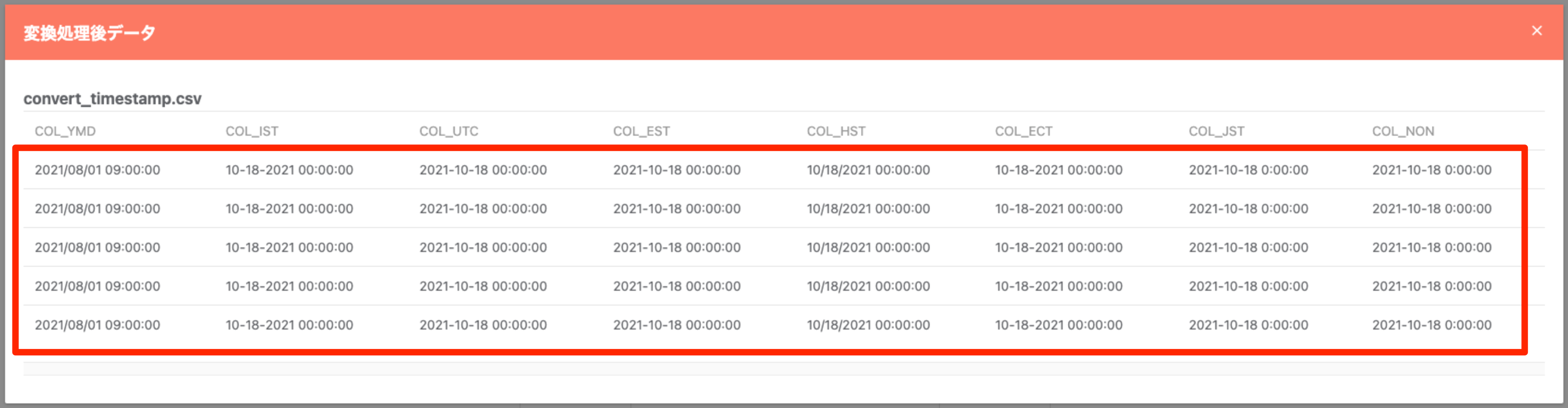
タイムスタンプ列 タイムゾーン統一¶
入力データソースで指定したタイムスタンプ項目の「タイムゾーン情報」を指定したものに変換・統一します。
Note
同一データソース内で異なるタイムゾーン設定の列が混在していた場合に便利です。
変換前のデータ列:
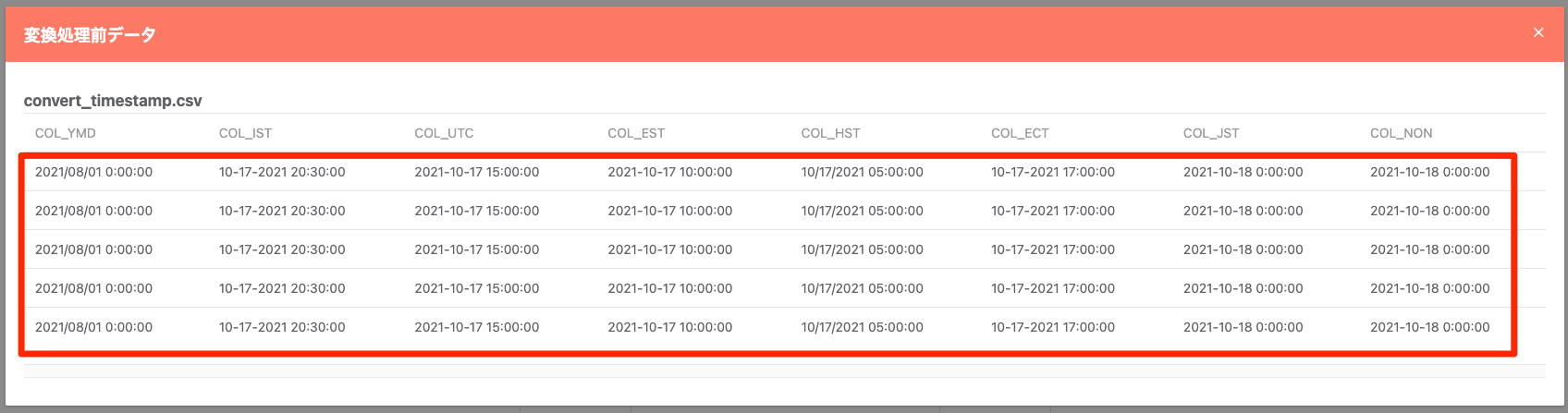
設定内容:
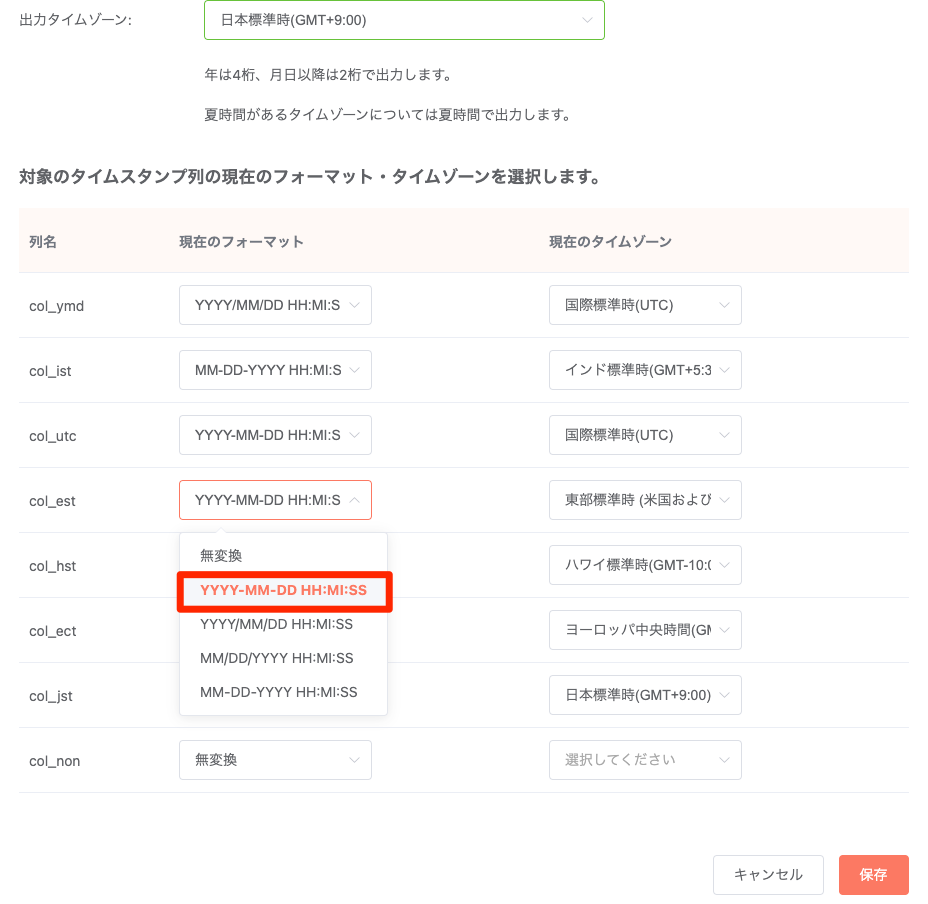
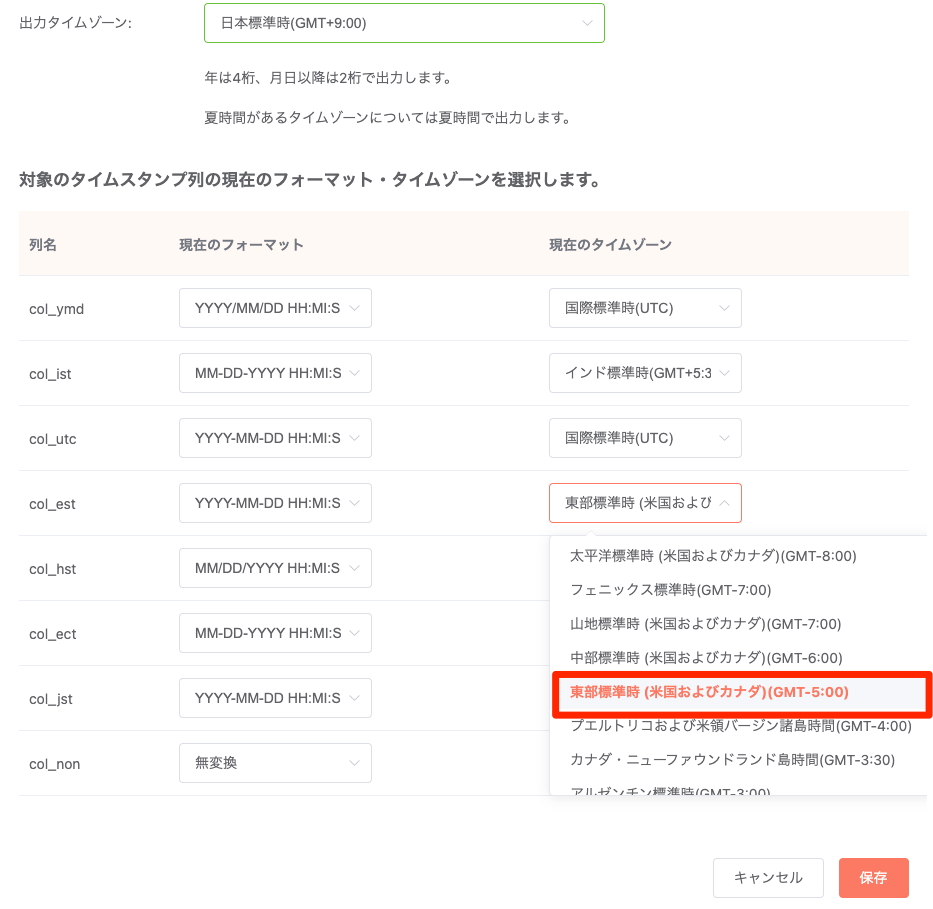
変換後のデータ列:
文字数統一¶
入力データソースの全カラムについて、各カラムの先頭から指定した文字数を抽出することで文字数を統一します。「部分抽出」で全カラムを対象とし、先頭から任意の文字数を抽出するよう指定した場合と同じ結果となります。
Note
ジョブ作成時にジョブ種別「データアップロード(for Redshift)」を選択した場合、変換・加工処理として文字数統一が初期設定されます。 この場合、抽出文字数の初期値は「65535」となります(65535はRedshiftのVARCHARの最大バイト数です)。
![]()